Right now I’m really interested in fine-tuning image classification models for whatever i can get my hands on. After the locating images assignment, I want to run a well known example of using image classification images to classify a timeseries data, as shown in the fastai book chapter one.
I found the notebook, and tried to rerun it to find out whether newer models can perform better.
Notes of the original notebook
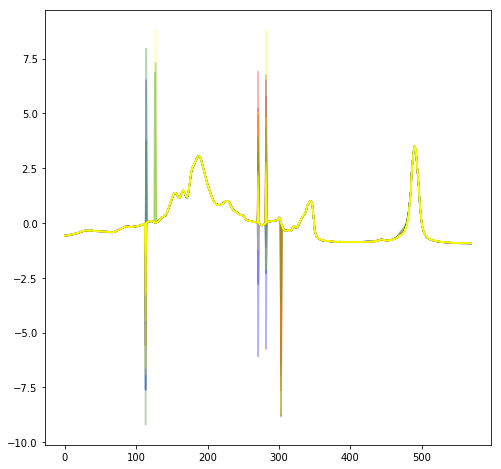
- I have downloaded the dataset from the mentioned source, but after rerunning the same cells from the notebook, I did not find the same pattern from the data. I presume that the data in the notebook has some errors, as in bitflips or improper decompression. This also makes it clear that the data from the source is already normalized in some way, so most of the data preprocessing is not needed.
 |
 |
| original graph with clear outlier data |
rerun data with much less variance |
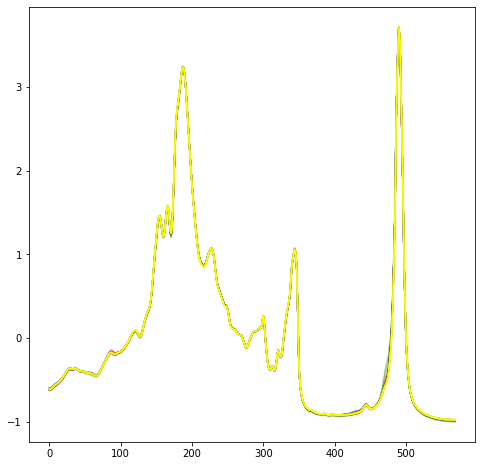
- The image saved from the notebook still contains the background and axis marks and ticks, instead of just the plot. This still preserves the 570x570 raw pixels though.
 |
 |
| original input data, with axes in the file |
rerun input data, plot only |
- The total training images produced are unclear. I assume the 30 original images are augmented with 30 noise add images.
Modifications in my run
- As the fastai module has progressed a lot since the time the notebook was published, I opt to fine tune the model using the .fine_tune convenience function, instead of running the functions manually.
- I’m only using the GADF plot as it is the best performing in the original notebook. I’m saving only the plot, without ticks and axis.
Original rerun
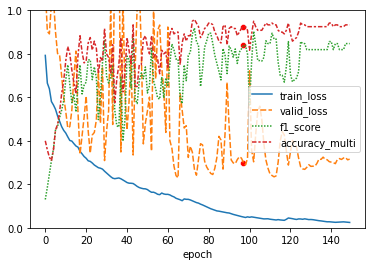
- I found that the mentioned performance is achievable, but through several runs and longer epochs. It’s probable that the data artifact in the original notebook is what causing the difference. But this rerun shows that the performance of fine-tuning image classifier models, on transformed timeseries dataset, is still very good.
- There’s a newer architecture called Vision Transformer that possibly can perform better, so I tried it with the original 30/30 training-test split.
- A hurdle in this is the timm sourced ViT model cannot accept larger images as the input. The ViT Model only accepts 384*384 input. This should be possible as described in the DEiT and SWIN papers (fine-tuning transformers using larger inputs results in better performance), but I have not found a way. So the images are resized using RandomResizedCropGPU to 384 pixels.
- I assume this would perform much worse as there will be data lost in the resize, as each pixel represents one time unit.
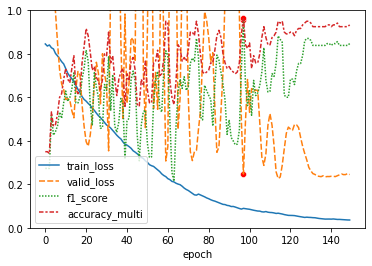
- Interestingly, after an unexpected training graph, the ViT model still can work fine, reaching similar performance levels of ResNet with the proper image.
Experimenting with rendering colormap
- The original notebook uses the
viridis colormap for GADF plots, but it only uses G and B pixels to render the map. I decided to try comparing the ‘rainbow’ cmap to the ‘viridis’ CMAP to find out if there is any difference.
- There is a slight difference and expected, as the viridis plots only uses 2 channels of information ,while the rainbow plot uses all three RGB channels. This might be an important point in using image classification techniques for timeseries data.
 |
|
| rainbow cmap |
viridis cmap |
Next
- For the topic of classifying time series data through image classification, there are several things I want to investigate, such as:
- Inputting the 1:1 representation to a transformer model
- Using the transformer architecture to infer arbitrary length timeseries data
- Cross Validation of the techniques using a different split of training/test data (40:20 or 45:15 or 50:10)